

GKE for your AI agents
Ok, so you’re writing an AI agent to automate some task (who isn’t these days?). But where does it live? That largely depends on what you want it to do.

Get in builder, we're writing agents
I’m a big proponent of starting as simple (i.e. managed) as possible, and going more complex when you need more functionality. On Google Cloud that means starting with a managed service like Gemini Enterprise Agent Platform where you can build a no-code agent, or deploy your code to a managed platform. Cloud Run is another compelling option for agents that are generally stateless and do basic tasks.
So why, then, would you use a more feature-rich platform like Google Kubernetes Engine (GKE) to run your agents?
It turns out, there are actually a lot of really compelling reasons to run your agents on GKE. Let’s look at a few of them.
Co-located Inference
Gemini is a fantastic choice for most agent brains, but sometimes, you might want to run an open-weight model (like Gemma 😉). If you’re going to host and manage the model yourself, there are good reasons to put it close to your agent logic.
For one, you can minimize network hops and latency. Multi-turn reasoning loops can be chatty, and each LLM call could add latency. If an agent is taking dozens of turns to complete a task, that can add up.
GKE lets you bring the “brain” directly to the workload. By co-locating open-weight models on the same GKE cluster as your agent logic, you completely bypass public network hops.
Workload Scenario: Imagine a specialized internal agent that uses a powerful external model like Gemini for its main reasoning loop, but it needs to convert a highly unique document format to a standard JSON. You could fine-tune an open model to handle this task directly, and let the main Gemini model focus on the reasoning. You get sub-millisecond “Agent-to-Inference” latency, keeping your agent’s loop snappy and cheap.
Secure Code Execution via Agent Sandbox
For a truly autonomous agent, code is the ultimate tool. Instead of hard-coding APIs or tools for every possible task, you might allow your agent to write and run its own scripts to solve complex problems. But executing untrusted, LLM-generated code is a bad idea. I mean, I trust the code Gemini produces… but to a point. Especially if users can influence what code is generated, you may end up with generated code that does something malicious.
GKE (and Kubernetes more broadly) solves this with Agent Sandbox, leveraging gVisor for kernel-level isolation. You can allow your agent to run code only in a secure container that restricts access to the host system and limits the potential damage from malicious code. That means any malicious code—intentional or not—is isolated to a single pod and won’t affect the rest of your cluster or any of your other workloads.

Keep your agent code isolated.
Workload Scenario: Imagine you’re building a financial analyst agent. You allow users to upload any files for analysis. You could build in tools for common file types, but what if someone has financial records in an older format you don’t usually see? Instead of just tossing the whole (probably binary) file into the context window, the agent could investigate the file format and write a custom Python script to handle it on the fly. GKE can spin up an isolated gVisor sandbox in milliseconds, run the script securely, extract the results, and terminate the sandbox. Potentially buggy or malicious code is completely isolated, and your core infrastructure remains safe.
Smart Traffic Routing: GKE Inference Gateway
Not all inference requests are the same. A basic agent might use Gemini for everything, or you could use Gemini for the reasoning, and then call out to a smaller local model for hard-coded specific tasks.
But what if you are managing multiple instances of a model, or even multiple models and need to intelligently route between them?
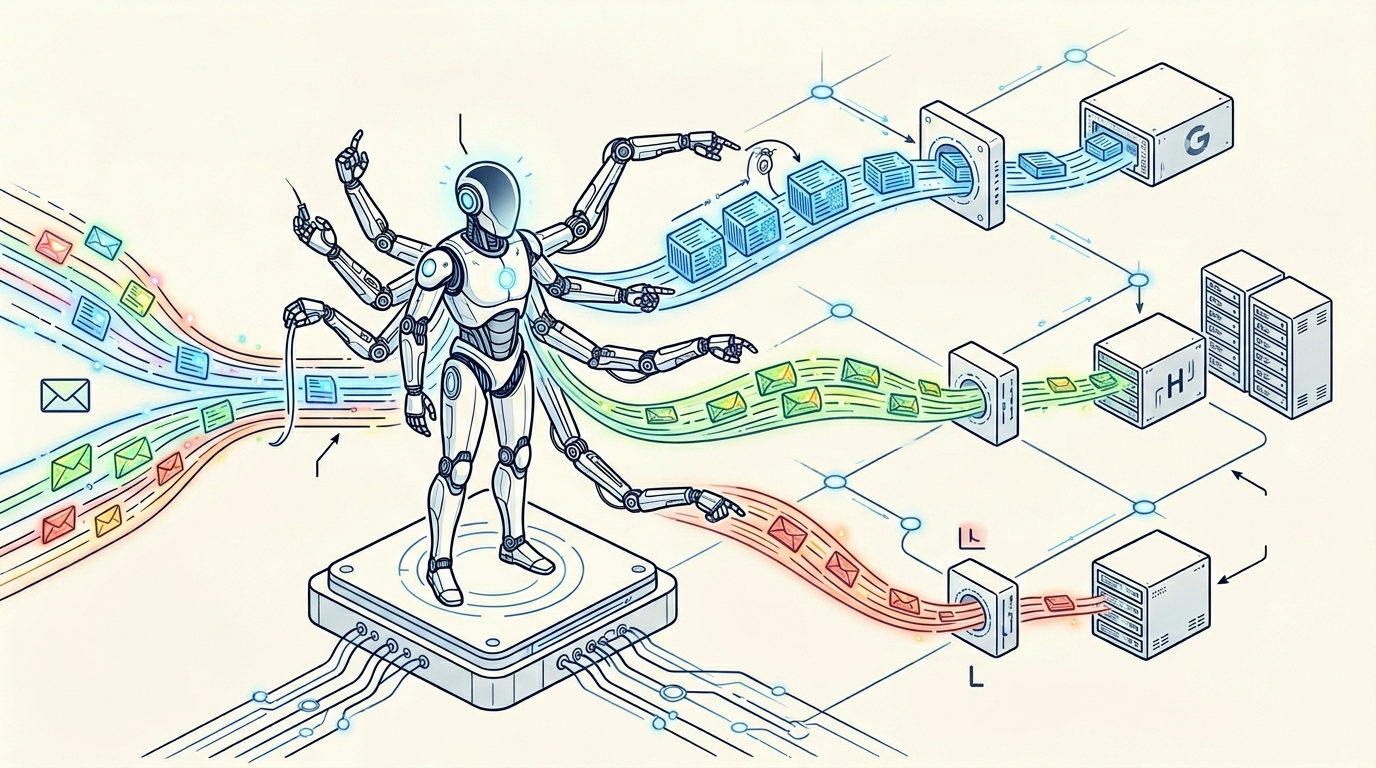
Smart routing for smart agents.
The GKE Inference Gateway (powered by the Gateway API Inference Extension) brings model-aware routing rules directly to the network layer. It acts as an intelligent dispatcher for your model servers. You can use it to route requests based on KV cache hits, accelerator utilization, or even based on the contents of the request body.
Because You Already Know and Love GKE!
If you are already running workloads on GKE, it could be a great fit for your agent, even if you don’t take advantage of GKE-specific features (yet!). You can start there and your agent will already be in GKE when you need the advanced stuff.
With GKE, AI agents are just another containerized workload.
You can leverage the Kubernetes knowledge you already have. You get native integration with Google Cloud Logging and easy integration with your existing CI/CD like Cloud Build.
Wrapping Up
There are a lot of cool reasons to run agents on GKE. I’m going to be exploring more about these topics in the coming weeks, so stay tuned for more in-depth guides on Agent Sandboxes, Inference Gateway and more!
What’s Next
- Try an Agent Sandbox Codelab
- Read more about Agents on GKE